
Tìm hiểu PageRank Google
PageRank là một thuật toán phân tích liên kết được phát triển tại Đại học Stanford bởi Larry Page. PageRank đặt theo tên của Larry Page ( Larry Page sinh ngày 26 tháng 3 năm 1973 là một nhà khoa học máy tính Mỹ, một doanh nhân internet, cùng với Sergey Brin là đồng sáng lập của Google. Tính đến ngày 04 tháng tư năm 2011, ông cũng là giám đốc điều hành của Google. Theo công bố của google vào ngày 20 tháng 4 năm 2011 tổng tài sản cá nhân của Larry Page ước tính là 16,7 tỷ USD )
Sau đó được Sergey Brin nghiên cứu phát triển thêm ( Mikhaylovich Sergey Brin (tiếng Nga là: Сергей Михайлович Брин, sinh ngày 21 tháng 8 năm 1973 là nhà khoa học máy tính Mỹ gốc Nga sinh ra ở Mỹ một doanh nhân internet. Cùng với Larry Page đồng sáng lập Google, một trong những công ty internet lớn nhất năm 2011, tài sản cá nhân của ông ước tính là 16,7 tỷ USD )
Thuật toán đó được Google sử dụng như một phần của công cụ tìm kiếm google search trong hệ thống xếp hạng trang Web của máy tìm kiếm nhằm sắp xếp thứ tự ưu tiên đường dẫn URL trong trang kết quả tìm kiếm.
Tên "PageRank" là thương hiệu của Google, nhưng bằng sáng chế PageRank được cấp cho Đại học Stanford ( mã bằng sáng chế US Patent 6.285.999 ) mà không cấp cho Google. Google đã phải chia 1.800.000 cổ phần cho Đại học Stanford để có quyền độc quyền giấy phép bằng sáng chế từ Đại học Stanford. Các cổ phiếu đã được bán trong năm 2005 với giá 336 triệu USD.
Theo Google một cách tóm lược thì PageRank chỉ được đánh giá từ hệ thống liên kết đường dẫn. Trang của bạn càng nhận nhiều liên kết trỏ đến thì mức độ quan trọng trang của bạn càng tăng. Tuy nhiên đó chỉ là những khái niệm sơ đẳng nhất mà Google hiếm khi thông báo chính thức. Trong thực tế, thuật toán PageRank phức tạp hơn rất nhiều. Và may mắn là như thế, nếu không trang kết quả tìm kiếm của Google sẽ không còn tin cậy bởi những người lạm dụng thuật toán của nó, và có lẽ như thế, SEO mới là một nghệ thuật làm tốn nhiều giấy bút của Webmaster.
PageRank của Google hiển thị trên GoogleToolbar ( Tải tại http://www.google.com/toolbar/ie/index.html ) là một số nguyên từ 0 cho đến 10. Đơn vị PageRank có tỷ lệ logarithmic dựa trên khối lượng link trỏ đến cũng như chất lượng của những trang Web chứ đường link xuất phát này.
Dưới đây là thuật toán trong nghiên cứu ban đầu của Larry Page và Sergey Brin.
Do quá phức tạp xin không được dịch. Ai rành tiếng Anh thì đọc để tham khảo nhé
Algorithm
PageRank is a
probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page. PageRank can be calculated for collections of documents of any size. It is assumed in several research papers that the distribution is evenly divided among all documents in the collection at the beginning of the computational process. The PageRank computations require several passes, called "iterations", through the collection to adjust approximate PageRank values to more closely reflect the theoretical true value.A probability is expressed as a numeric value between 0 and 1. A 0.5 probability is commonly expressed as a "50% chance" of something happening. Hence, a PageRank of 0.5 means there is a 50% chance that a person clicking on a random link will be directed to the document with the 0.5 PageRank.
Simplified algorithm
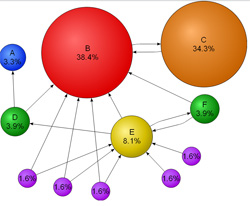
Assume a small universe of four web pages: A, B, C and D. The initial approximation of PageRank would be evenly divided between these four documents. Hence, each document would begin with an estimated PageRank of 0.25.
In the original form of PageRank initial values were simply 1. This meant that the sum of all pages was the total number of pages on the web at that time. Later versions of PageRank (see the formulas below) would assume a probability distribution between 0 and 1. Here a simple probability distribution will be used—hence the initial value of 0.25.
If pages B, C, and D each only link to A, they would each confer 0.25 PageRank to A. All PageRank PR( ) in this simplistic system would thus gather to A because all links would be pointing to A.
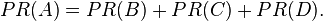
This is 0.75.
Suppose that page B has a link to page C as well as to page A, while page D has links to all three pages. The value of the link-votes is divided among all the outbound links on a page. Thus, page B gives a vote worth 0.125 to page A and a vote worth 0.125 to page C. Only one third of D's PageRank is counted for A's PageRank (approximately 0.083).

In other words, the PageRank conferred by an outbound link is equal to the document's own PageRank score divided by the normalized number of outbound links L( ) (it is assumed that links to specific URLs only count once per document).
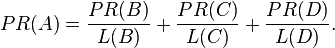
In the general case, the PageRank value for any page u can be expressed as:
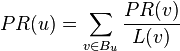 ,
,
i.e. the PageRank value for a page u is dependent on the PageRank values for each page v out of the set Bu (this set contains all pages linking to page u), divided by the number L(v) of links from page v.
Damping factor
The PageRank theory holds that even an imaginary surfer who is randomly clicking on links will eventually stop clicking. The probability, at any step, that the person will continue is a damping factor d. Various studies have tested different damping factors, but it is generally assumed that the damping factor will be set around 0.85.
The damping factor is subtracted from 1 (and in some variations of the algorithm, the result is divided by the number of documents (N) in the collection) and this term is then added to the product of the damping factor and the sum of the incoming PageRank scores. That is,
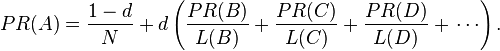
So any page's PageRank is derived in large part from the PageRanks of other pages. The damping factor adjusts the derived value downward. The original paper, however, gave the following formula, which has led to some confusion:
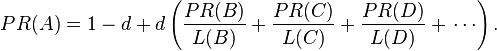
The difference between them is that the PageRank values in the first formula sum to one, while in the second formula each PageRank gets multiplied by N and the sum becomes N. A statement in Page and Brin's paper that "the sum of all PageRanks is one"[4] and claims by other Google employees support the first variant of the formula above.
To be more specific, in the latter formula, the probability for the random surfer reaching a page is weighted by the total number of web pages. So, in this version PageRank is an expected value for the random surfer visiting a page, when he restarts this procedure as often as the web has pages. If the web had 100 pages and a page had a PageRank value of 2, the random surfer would reach that page in an average twice if he restarts 100 times. Basically, the two formulas do not differ fundamentally from each other. A PageRank that has been calculated by using the former formula has to be multiplied by the total number of web pages to get the according PageRank that would have been calculated by using the latter formula. Even Page and Brin mixed up the two formulas in their most popular paper "The Anatomy of a Large-Scale Hypertextual Web Search Engine", where they claim the latter formula to form a probability distribution over web pages with the sum of all pages' PageRanks being one.
Google recalculates PageRank scores each time it crawls the Web and rebuilds its index. As Google increases the number of documents in its collection, the initial approximation of PageRank decreases for all documents.
The formula uses a model of a random surfer who gets bored after several clicks and switches to a random page. The PageRank value of a page reflects the chance that the random surfer will land on that page by clicking on a link. It can be understood as a
Markov chain in which the states are pages, and the transitions are all equally probable and are the links between pages.If a page has no links to other pages, it becomes a sink and therefore terminates the random surfing process. If the random surfer arrives at a sink page, it picks another
URL at random and continues surfing again.When calculating PageRank, pages with no outbound links are assumed to link out to all other pages in the collection. Their PageRank scores are therefore divided evenly among all other pages. In other words, to be fair with pages that are not sinks, these random transitions are added to all nodes in the Web, with a residual probability of usually d = 0.85, estimated from the frequency that an average surfer uses his or her browser's bookmark feature.
So, the equation is as follows:
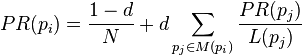
where p1,p2,...,pN are the pages under consideration, M(pi) is the set of pages that link to pi, L(pj) is the number of outbound links on page pj, and N is the total number of pages.
The PageRank values are the entries of the dominant
eigenvector of the modified adjacency matrix. This makes PageRank a particularly elegant metric: the eigenvector is
where R is the solution of the equation
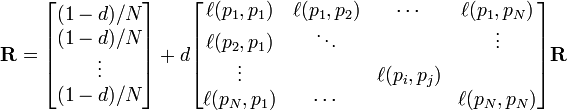
where the adjacency function 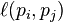 is 0 if page pj does not link to pi, and normalized such that, for each j
is 0 if page pj does not link to pi, and normalized such that, for each j
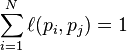 ,
,
i.e. the elements of each column sum up to 1, so the matrix is a
stochastic matrix (for more details see the computation section below). Thus this is a variant of the eigenvector centralitymeasure used commonly in network analysis.Because of the large eigengap of the modified adjacency matrix above, the values of the PageRank eigenvector are fast to approximate (only a few iterations are needed).
As a result of
Markov theory, it can be shown that the PageRank of a page is the probability of being at that page after lots of clicks. This happens to equal t − 1 where t is theexpectation of the number of clicks (or random jumps) required to get from the page back to itself.The main disadvantage is that it favors older pages, because a new page, even a very good one, will not have many links unless it is part of an existing site (a site being a densely connected set of pages, such as
Wikipedia). The Google Directory (itself a derivative of the Open Directory Project) allows users to see results sorted by PageRank within categories. The Google Directory is the only service offered by Google where PageRank directly determines display order. In Google's other search services (such as its primary Web search) PageRank is used to weight the relevance scores of pages shown in search results.Several strategies have been proposed to accelerate the computation of PageRank.
Various strategies to manipulate PageRank have been employed in concerted efforts to improve search results rankings and monetize advertising links. These strategies have severely impacted the reliability of the PageRank concept, which seeks to determine which documents are actually highly valued by the Web community.
Google is known to penalize
link farms and other schemes designed to artificially inflate PageRank. In December 2007 Google started actively penalizing sites selling paid text links. How Google identifies link farms and other PageRank manipulation tools are among Google's trade secrets.Iterative
In the former case, at t = 0, an initial probability distribution is assumed, usually
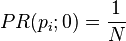 .
.
At each time step, the computation, as detailed above, yields
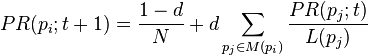 ,
,
or in matrix notation
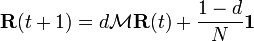 , (*)
, (*)
where 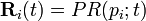 and
and 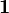 is the column vector of length N containing only ones.
is the column vector of length N containing only ones.
The matrix  is defined as
is defined as

i.e.,
 ,
,
where A denotes the
adjacency matrix of the graph and K is the diagonal matrix with the outdegrees in the diagonal.The computation ends when for some small 
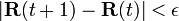 , i.e., when convergence is assumed.
, i.e., when convergence is assumed.
Algebraic
In the latter case, for
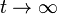 (i.e., in the
(i.e., in the
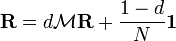 . (**)
. (**)
The solution is given by
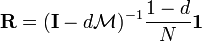 ,
,
with the
identity matrix .
.
The solution exists and is unique for 0 < d < 1. This can be seen by noting that is by construction a
Power Method
If the matrix is a transition probability, i.e., column-stochastic with no columns consisting of just zeros and 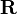 is a probability distribution (i.e.,
is a probability distribution (i.e.,  ,
,  where
where 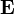 is matrix of all ones), Eq. (**) is equivalent to
is matrix of all ones), Eq. (**) is equivalent to
 . (***)
. (***)
Hence PageRank is the principal eigenvector of 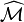 . A fast and easy way to compute this is using the
. A fast and easy way to compute this is using the
is applied in succession, i.e.,
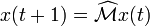 ,
,
until
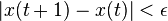 .
.
Note that in Eq. (***) the matrix on the right-hand side in the parenthesis can be interpreted as
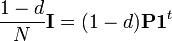 ,
,
where 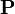 is an initial probability distribution. In the current case
is an initial probability distribution. In the current case
 .
.
Finally, if has columns with only zero values, they should be replaced with the initial probability vector . In other words
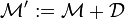 ,
,
where the matrix 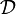 is defined as
is defined as
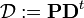 ,
,
with

In this case, the above two computations using only give the same PageRank if their results are normalized:
 .
.
ICT GROUP tổng hợp và dịch từ nhiều nguồn. Tham khảo http://en.wikipedia.org/wiki/PageRank
Tin khác
![]() Hướng dẫn kiểm tra tối ưu trang Web với Google Page speed
Hướng dẫn kiểm tra tối ưu trang Web với Google Page speed
![]() Một số thông tin cơ bản về SEO
Một số thông tin cơ bản về SEO
![]() Tabs và SEO: Những điều bạn cần xem xét
Tabs và SEO: Những điều bạn cần xem xét
![]() Tối ưu hoá Công cụ Tìm kiếm (SEO)
Tối ưu hoá Công cụ Tìm kiếm (SEO)
![]() Các công cụ phân tích từ khóa trực tuyến tốt nhất
Các công cụ phân tích từ khóa trực tuyến tốt nhất
![]() Những bước cơ bản để tự SEO quảng bá website
Những bước cơ bản để tự SEO quảng bá website
![]() Kỹ thuật marketing Quảng bá website
Kỹ thuật marketing Quảng bá website
![]() Google Ad Manager cho Publisher
Google Ad Manager cho Publisher